
AI use in L&D is rising fast, but prompt quality often lags behind. Poor inputs lead to weak outputs, wasted time and reduced learner trust. Drawing on the testing methodologies of verification and validation, together with Dakan and Feller’s 4Ds framework, Catherine Dock explains how to strengthen your AI prompts
We know from recent L&D research that Learning teams are using AI more widely to support increased volumes of L&D design delivery, and personalisation of learning at scale. This trend is reflected across several studies and industry insights, including AI in L&D: The Race for Impact; How Gen AI Could Transform Learning and Development; and the CIPD podcast episode Evidence-based L&D – The gift of artificial intelligence.
“Using this framework has stopped me using my AI tools like I’m searching on Google and helped me turn my prompts into meaningful conversations with a useful assistant”
As in other specialisms, there has been an acceleration in use over the last three years, as AI technology has developed and more non-technical individuals have been exposed to AI tools, particularly in generative AI.
However, in the use of AI to improve productivity efficiencies and effectiveness, inferior quality prompts can lead to poorer quality outputs – a case of “rubbish in, rubbish out.” This can include inconsistency, bias or ineffectiveness in training outcomes and damage the intended positive use of AI, and result in taking more time and effort to then produce the outcomes required.
In this article, I’m going to explain the definitions and practical applications of verification and validation testing methodologies, and how these can overlay against a comprehensive approach to AI prompting provided by one of the major AI companies.
From an L&D perspective, in applying the combination of verification and validation methodologies to crafting AI inputs, this gives rigour to the process to support pedagogical integrity, ie what is generated; and improved learner trust.
By the end of this article, you will have an idea of how to apply this framework to improve your prompts’ quality, substance and better inform the outputs for your needs.
What verification and validation really mean
How can Learning teams ensure that their inputs are high quality and support the best outcomes for end users? From my days in software testing, a simple proof is used, a set of core principles that one of the first things that trainee testers learn – verification and validation. In simple terms this is:
- Verification: Did we build the system right? Does the system delivered meet the specifications and requirements specified in design?
- Validation: Did we build the right system? Does the system built really deliver those specifications as intended for end users?
It should be noted that there is a dedicated international standard for verification and validation for AI systems – ISO42001, as exemplified by ISMS’s David Holloway and IT Governance. It provides: “…a structured framework and clear requirements for organisations to establish, implement, maintain, and continually improve responsible AI governance – from design through deployment and monitoring”.
However, for the purposes we need, this doesn’t specifically cover Learning and Development in concert with AI systems, so we will extend that link ourselves.
Introducing Dakan and Feller’s ‘4Ds’
The second element that I’m going to overlay stems from an excellent set of training I experienced through Anthropic, (here and here) who own and develop the Claude AI tool set. They proffer a ‘4Ds’ framework for GenAI prompting, originally developed by professor Rick Dakan from the Ringling College of Art and Design, Florida, and professor Joseph Feller from the Cork University Business School, University College Cork, Ireland. Dakan and Feller’s work explores the intersection between (1) human creativity and innovation, (2) generative AI technologies (GenAI), and (3) learning and teaching in higher education.
The 4Ds framework guides users into writing smarter prompts to get better outputs from the tool:
- Delegation: Thoughtfully deciding what work to do with AI versus doing yourself.
- Description: Communicating clearly with AI systems.
- Discernment: Evaluating AI outputs and behaviour with a critical eye.
- Diligence: Ensuring you interact with AI responsibly.
I really like the structure of this framework and the way inputs are designed to be considered with thought and rigour to improve the outputs from the AI to provide greater value to the user. It also has a balance between the four elements of the framework. Using this framework has stopped me using my AI tools like I’m searching on Google and helped me turn my prompts into meaningful conversations with a useful assistant.
A couple of good examples in the field of considerations for AI, including ethical considerations, can be found on Lumenalta’s website and the UK College of Policing.
How verification and validation applies to L&D
I’ve given a basic definition of verification and validation above. Let’s now define them in the context of Learning and Development:
- Verification: testing whether training prompts, AI-generated learning materials, or assessments work as intended and align with instructional design goals.
- Validation: evaluating whether the resulting learner experiences and outcomes are meaningful, accurate, and aligned with learning objectives.
As a former tester, I can tell you that validation can often lead to the realisation that the requirements driving the verification are flawed! Therefore, it’s important that Learning teams really understand what their objectives and requirements are and that these are accurate against both expected performance indicators and stakeholder expectations.
Applying each of the 4Ds for verification and validation against this learning context, we can show this in the following summarised framework:
| Verification (Have we built the system right) | Validation (Have we built the right system) | |
| Delegation | Evaluate how prompts clarify the AI’s instructional role (coach, tutor, assessor). | Measure AI’s effectiveness in enhancing rather than replacing human facilitation. |
| Description | Prompts are clear, contextual, and educationally sound (aligning with Bloom’s taxonomy or similar frameworks). | Confirm that output contain performance expectations (tone, depth, interactivity) suited to learner level. |
| Discernment | AI outputs meet pedagogical quality standards and learner needs. | Analyse the AI’s interaction quality: are learners prompted to think critically rather than simply consume content? |
| Diligence | Ensure privacy, bias mitigation, and legal or regulatory requirements in AI-generated outputs have been properly addressed before finalisation or deployment. | Review the outputs are fit for purpose in terms of factual integrity, fairness, accessibility, and risk mitigation; transparency for stakeholders of AI’s involvement in the process, and confirm that final results meet organisational, legal, and ethical benchmarks. |
Let’s dig into each of these in more detail, with some examples.
Delegation: Setting the boundaries of AI in learning
Apply delegation to instructional design decisions – so choosing which elements of content creation, feedback, or coaching to automate or co-create with AI.
Considerations are not limited to, but could include:
- Automating quiz generation but validating that it still aligns with the course’s core learning objectives.
- Using AI to summarise coaching sessions (within the bounds of confidentiality) while verifying factual and tone accuracy.
To put this into perspective, it’s considering the requirements and problems to be solved and the scoping of those tasks that these address. In defining what the AI will be assisting with, this provides our first test of prompt quality.
Description: Designing verifiable and aligned prompts
In L&D, description ensures that prompts are clear, contextual, and educationally sound (aligning with Bloom’s taxonomy or similar frameworks). They should also contain performance expectations (tone, depth, interactivity) suited to learner level.
Considerations are not limited to, but could include:
- Creating reusable prompt templates verified through peer or subject matter expert (SME) approval.
- Incorporating product, process, and performance descriptions for AI-driven courses or microlearning modules.
- Verifying that an AI-generated case study prompt adheres to cognitive or experiential learning models.
We can describe Description as the blueprint that makes the prompt verification and validation measurable through providing measurable performance indicators from expected outcomes.
Discernment: Validating learning quality and impact
Discernment is a validation method for ensuring AI outputs meet pedagogical quality standards and learner needs. Considerations are not limited to, but could include:
- Product discernment: Review AI-generated learning materials for instructional coherence so they make sense and are inclusive for all learners.
- Process discernment: Analyse the AI’s interaction quality – are learners being prompted to think critically rather than simply consume content?
- Performance discernment: Observe learner engagement and comprehension to validate outcomes.
Learning teams should consider implementing iterative validation cycles – such as pilot learning content, gather learner feedback, refine and redeploy – so each implementation and testing cycle builds on the previous one, particularly for the description and discernment parts of the cycle. This approach also supports good practice in structured recording and tracking the inputs and outputs in each iteration, so teams can compare like-for-like.
Diligence: Embedding accountability and transparency
Diligence translates responsible AI usage into corporate and learning at scale. Verification and validation practices here ensure:
- Ethical creation (eg minimising bias in training datasets).
- Transparent communication (documenting AI’s role in course generation or feedback).
- Reliable deployment (ensuring final materials are accurate, accessible, and data-secure).
Good practice here is encouraging Learning teams to maintain a ’Learning AI diligence statement’ outlining:
- What AI tools were used and for what purpose.
- Verification and validation testing methods applied.
- Accountability structure for learning outcomes.
Regular reviews against the items in the diligence statement ensure continued focus so that ethical processes are followed and sustained. Unesco produced a guidance document on this.
Creating an AI quality loop for L&D
How do we turn this into an even more powerful tool? As I alluded to in discernment, we can integrate each of the 4Ds into an ongoing AI-powered learning verification and validation loop:
- Delegation: Decide when and how AI assists instructional design.
- Description: Develop and verify precise prompts guiding AI tasks.
- Discernment : Validate AI’s performance and learner outcomes.
- Diligence: Document and ensure responsible implementation.
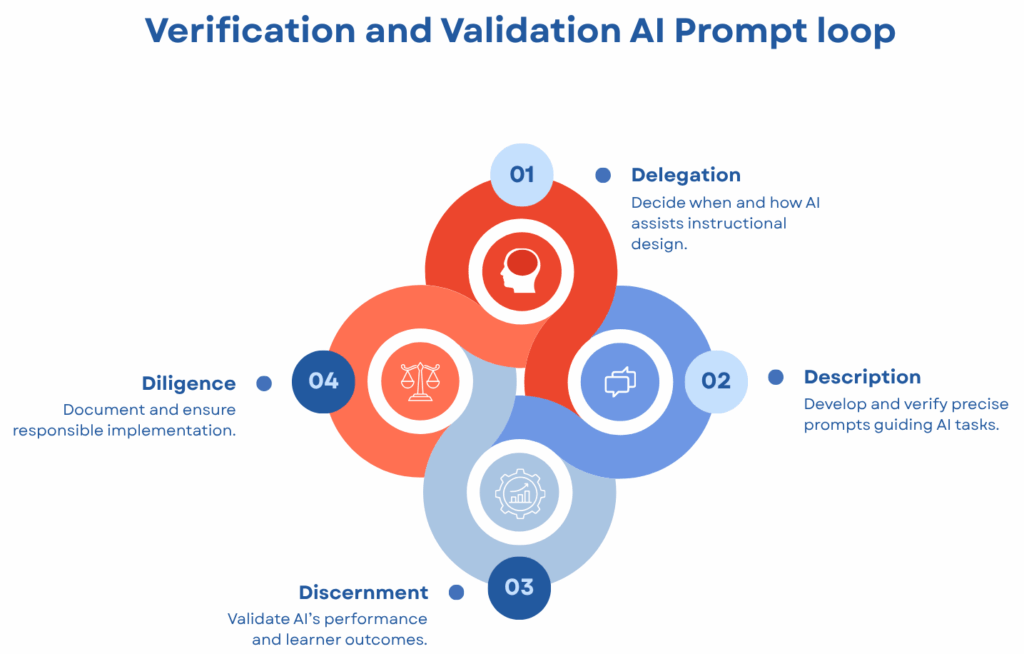
Figure 1: AI Quality Loop for L&D using the Anthropic 4Ds
This cycle mirrors continuous improvement models like ADDIE or Kirkpatrick’s Evaluation Levels but recontextualised for AI collaboration and data-driven learning assurance.
Measuring outcomes for L&D stakeholders
Whenever we create learning programmes and deliverables, these should have a sense of purpose to drive:
- More consistent and scalable content quality.
- Enhanced instructional design efficiency without pedagogical trade-offs.
- Increased learner trust through transparent and validated AI interactions.
- Providing a sustainable ethical governance model for AI integration in training.
Therefore, we should find metrics, whether quantitative or qualitative, that allow proof that the AI-enabled learning has met its goals.
Here are some examples of learning KPIs for each of the 4Ds, generated with some assistance from the Perplexity AI tool, which uses Claude Sonnet 4.5 as one of its source models:
| Category | Example Metric | Learning Impact |
| Delegation | ||
| Task Alignment | % of AI tasks aligned with instructional objectives | Ensures AI supports valid learning outcomes |
| AI Utilisation Efficiency | Time saved through automation vs. manual creation | Quantifies the productivity gain from delegation |
| Role Clarity | Instances of misaligned or redundant tasks between trainers and AI | Indicates precision in human–AI task design |
| Description | ||
| Prompt Precision | % of prompts producing desired format and scope | Tracks structural accuracy in learning output |
| Cognitive Alignment | Match rate between AI content and target Bloom’s taxonomy levels | Validates cognitive appropriateness |
| Learner Comprehension Rate | Pre-/post-test alignment with AI learning content | Measures whether verified prompts yield real understanding |
| Discernment | ||
| Content Accuracy | % of AI-generated learning content passing SME vetting | Ensures knowledge reliability |
| Engagement Quality | Learner satisfaction or relevance scores | Validates resonance of AI-generated material |
| Iteration Effectiveness | Improvement rate between AI enhancements over cycles | Monitors continuous quality refinement |
| Diligence | ||
| Transparency | % of AI-assisted modules clearly labelled as such | Upholds learner trust |
| Bias Reduction | Score from fairness and inclusion audit | Ensures representational equity |
| Compliance Validation | Training modules meeting ISO/EEOC or internal ethics standards | Guarantees regulatory alignment |
| Diligence Adoption Rate | % of courses featuring a prompt audit or Diligence Statement | Measures institutional responsibility maturity |
Raising the bar for AI in L&D
In summary, using verification and validation methodologies in combination with Dakan and Feller’s 4Ds framework can enable Learning teams to evolve from experimentation to a disciplined and standardised prompt evaluation framework. Applying these concepts in concert raises the standards, fluency, precision, and accountability in prompt design.
I’d end by encouraging readers to experiment with your chosen AI models and tools using the framework to learn how you can interact with it to get the best results.
Catherine Dock is Senior Learning and Development Consultant at Stellar Shift Consulting Limited

